- Graph
- DFS
- BFS
- Dijkstra
Graph

- 정의 : 노드의 상하위 개념이 없고, 노드(혹은 버텍스)와 노드들을 잇는 엣지로 구성되어 있는 자료구조
- 용어
- 정점(vertex): 위치라는 개념. (node 라고도 부름)
- 간선(edge): 위치 간의 관계. 즉, 노드를 연결하는 선 (link, branch 라고도 부름)
- 인접 정점(adjacent vertex): 간선에 의 해 직접 연결된 정점
- 정점의 차수(degree): 무방향 그래프에서 하나의 정점에 인접한 정점의 수
- 무방향 그래프에 존재하는 정점의 모든 차수의 합 = 그래프의 간선 수의 2배
- 진입 차수(in-degree): 방향 그래프에서 외부에서 오는 간선의 수 (내차수 라고도 부름)
- 진출 차수(out-degree): 방향 그래픙에서 외부로 향하는 간선의 수 (외차수 라고도 부름)
- 방향 그래프에 있는 정점의 진입 차수 또는 진출 차수의 합 = 방향 그래프의 간선의 수(내차수 + 외차수)
- 경로 길이(path length): 경로를 구성하는 데 사용된 간선의 수
- 단순 경로(simple path): 경로 중에서 반복되는 정점이 없는 경우
- 사이클(cycle): 단순 경로의 시작 정점과 종료 정점이 동일한 경우
- 특징
- 노드들 사이에 무방향/방향에서 양방향 경로를 가질 수 있다.
- self-loop 뿐 아니라 loop/circuit 모두 가능하다.
- 루트 노드라는 개념이 없다.
- 부모-자식 관계라는 개념이 없다.
- 순회는 DFS나 BFS로 이루어진다.
- 트리는 그래프의 한 종류이다.
- 그래프 종류
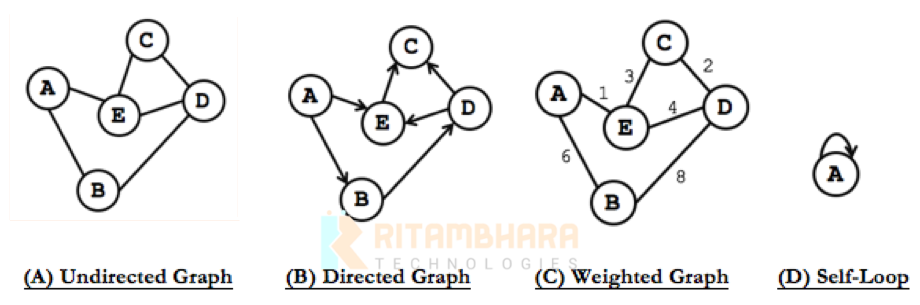
- 무방향 그래프(Undirected Graph) : 무방향 그래프의 간선은 간선을 통해서 양 방향으로 갈 수 있다.
- 방향 그래프(Directed Graph) : 간선에 방향성이 존재하는 그래프
- 가중치 그래프(Weighted Graph) : 간선에 비용이나 가중치가 할당된 그래프
- 연결 그래프(Connected Graph) : 무방향 그래프에 있는 모든 정점쌍에 대해서 항상 경로가 존재하는 경우
- 비연결 그래프(Disconnected Graph) : 무방향 그래프에서 특정 정점쌍 사이에 경로가 존재하지 않는 경우
- 사이클(Cycle) : 단순 경로의 시작 정점과 종료 정점이 동일한 경우
- 단순 경로(Simple Path): 경로 중에서 반복되는 정점이 없는 경우
- 비순환 그래프(Acyclic Graph) : 사이클이 없는 그래프
- 완전 그래프(Complete Graph) : 그래프에 속해 있는 모든 정점이 서로 연결되어 있는 그래프
- 구현방법

인접리스트
- 모든 정점(혹은 노드)을 인접 리스트에 저장한다. 즉, 각각의 정점에 인접한 정점들을 리스트로 표시한 것
- 장점
- 어떤 노드에 인접한 노드들 을 쉽게 찾을 수 있다.
- 그래프에 존재하는 모든 간선의 수 는 O(N+E) 안에 알 수 있다. : 인접 리스트 전체를 조사
- 단점 : 두 정점을 연결하는 간선의 존재 여부를 아는데 시간이 오래걸린다. O(V)
인접행렬
- 인접 행렬은 NxN 불린 행렬(Boolean Matrix)로써 matrix[i][j]가 true라면 i -> j로의 간선이 있다는 뜻
- 장점
- 구현이 쉽다.
- 두 정점을 연결하는 간선의 존재 여부를 O(1) 안에 즉시 알 수 있다. : M[i][j]
- 정점의 차수 는 O(N) 안에 알 수 있다. : 인접 배열의 i번 째 행 또는 열을 모두 더한다
- 단점
- 특정 노드에 인접한 노드들을 찾기 위해서는 모든 노드를 전부 순회해야 한다. ON)
- 그래프에 존재하는 모든 간선의 수는 O(N^2) 안에 알 수 있다. : 인접 행렬 전체를 조사한다.
Graph Search
DFS, Depth-First-Search
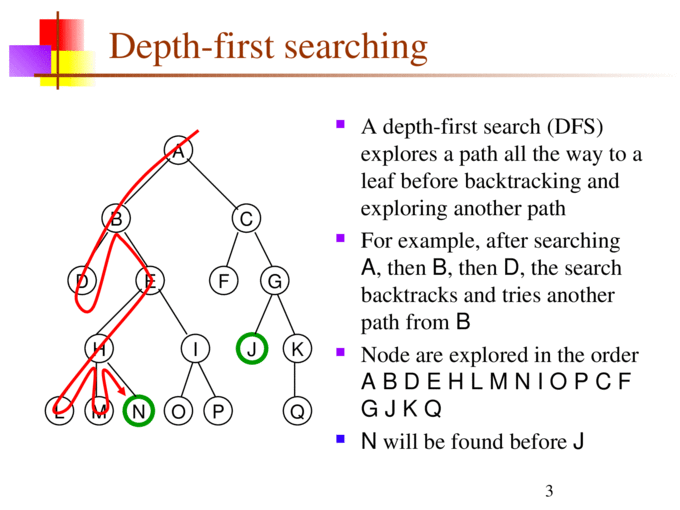
- 정의 : 시작점에서 노드를 따라 끝까지 간 후, leaf node를 만나게 되면 다시 제자리로 돌아와서 탐색
- 의사코드
- a 노드(시작 노드)를 방문한다. 방문한 노드는 방문했다고 표시한다.
- a와 인접한 노드들을 차례로 순회한다. a와 인접한 노드가 없다면 종료한다.
- a와 이웃한 노드 b를 방문했다면, a와 인접한 또 다른 노드를 방문하기 전에 b의 이웃 노드들을 전부 방문해야 한다.
- b를 시작 정점으로 DFS를 다시 시작하여 b의 이웃 노드들을 방문한다.
- b의 분기를 전부 완벽하게 탐색했다면 다시 a에 인접한 정점들 중에서 아직 방문이 안 된 정점을 찾는다.
즉, b의 분기를 전부 완벽하게 탐색한 뒤에야 a의 다른 이웃 노드를 방문할 수 있다는 뜻이다. - 아직 방문이 안 된 정점이 없으면 종료한다. 있으면 다시 그 정점을 시작 정점으로 DFS를 시작한다
- DFS 시간복잡도
- 인접 리스트로 표현된 그래프: O(N+E)
- 인접 행렬로 표현된 그래프: O(N^2)
BFS, Breath-First-Search
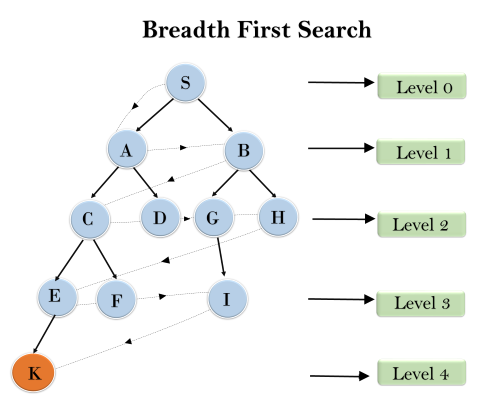
- 정의 : 루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법. 시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문
- 의사코드
- a 노드(시작 노드)를 방문한다. (방문한 노드 체크)
- 큐에 방문된 노드를 삽입(enqueue)한다.
- 초기 상태의 큐에는 시작 노드만이 저장
- 즉, a 노드의 이웃 노드를 모두 방문한 다음에 이웃의 이웃들을 방문한다.
- 큐에서 꺼낸 노드과 인접한 노드들을 모두 차례로 방문한다.
- 큐에서 꺼낸 노드를 방문한다.
- 큐에서 커낸 노드과 인접한 노드들을 모두 방문한다.
- 인접한 노드가 없다면 큐의 앞에서 노드를 꺼낸다(dequeue).
- 큐에 방문된 노드를 삽입(enqueue)한다.
- 큐가 소진될 때까지 계속한다.
- BFS 시간복잡도
- 인접 리스트로 표현된 그래프: O(N+E)
- 인접 행렬로 표현된 그래프: O(N^2)
Shortest path

Dijkstra algorithm
- 정의 : 그래프에서 노드 사이의 최단 경로를 찾는 알고리즘
- 의사코드 (P[A][B]는 A와 B 사이의 거리라고 가정한다)
-
출발점으로부터의 최단거리를 저장할 배열 d[v]를 만들고, 출발 노드에는 0을, 출발점을 제외한 다른 노드들에는 매우 큰 값 INF를 채워 넣는다. (정말 무한이 아닌, 무한으로 간주될 수 있는 값을 의미한다.) 보통은 최단거리 저장 배열의 이론상 최대값에 맞게 INF를 정한다. 실무에서는 보통 d의 원소 타입에 대한 최대값으로 설정하는 편.
-
현재 노드를 나타내는 변수 A에 출발 노드의 번호를 저장한다.
-
A로부터 갈 수 있는 임의의 노드 B에 대해, d[A] + P[A][B]와 d[B]의 값을 비교한다. INF와 비교할 경우 무조건 전자가 작다.
-
만약 d[A] + P[A][B]의 값이 더 작다면, 즉 더 짧은 경로라면, d[B]의 값을 이 값으로 갱신시킨다.
-
A의 모든 이웃 노드 B에 대해 이 작업을 수행한다.
-
A의 상태를 "방문 완료"로 바꾼다. 그러면 이제 더 이상 A는 사용하지 않는다.
-
"미방문" 상태인 모든 노드들 중, 출발점으로부터의 거리가 제일 짧은 노드 하나를 골라서 그 노드를 A에 저장한다.
-
도착 노드가 "방문 완료" 상태가 되거나, 혹은 더 이상 미방문 상태의 노드를 선택할 수 없을 때까지, 3~7의 과정을 반복한다.
- 도착 노드에 저장된 값이 바로 A로부터의 최단 거리. 만약 이 값이 INF라면, 중간에 길이 끊긴 것임을 의미.
예시코드
// BOJ 1260 - DFS, BFS
// input
// 첫째 줄에 정점의 개수 N(1 ≤ N ≤ 1,000), 간선의 개수 M(1 ≤ M ≤ 10,000),
// 탐색을 시작할 정점의 번호 V가 주어진다. 다음 M개의 줄에는 간선이 연결하는 두 정점의 번호가 주어진다.
// 어떤 두 정점 사이에 여러 개의 간선이 있을 수 있다. 입력으로 주어지는 간선은 양방향이다.
// output
// 첫째 줄에 DFS를 수행한 결과를, 그 다음 줄에는 BFS를 수행한 결과를 출력한다.
#include <iostream>
#include <vector>
#include <queue>
#include <algorithm> // sort()함수
using namespace std;
vector< vector<int> > graph; // 인접리스트로 구현된 그래프
vector<bool> visited; // 정점 방문여부를 기록하기 위한 배열
void DFS(int start);
void BFS(int start);
int main(void) {
int N; //정점(vertex)의 갯수
int M; //간선(edge)의 갯수
int V; // 탐색 시작할 정점의 번호
cin >> N >> M >> V;
graph.resize(N + 1); // 정점을 번호를 그대로 인덱스로 사용하기 위해 n+1의 크기 할당
visited.resize(N + 1); // 정점을 번호를 그대로 인덱스로 사용하기 위해 n+1의 크기 할당
for (int m = 0; m < M; m++) { // 두 정점 연결
int v1, v2;
cin >> v1 >> v2;
graph[v1].push_back(v2);
graph[v2].push_back(v1);
}
DFS(V);
cout << endl;
visited.resize(0); // 방문 기록 초기화
visited.resize(N + 1);
BFS(V);
return 0;
}
void DFS(int start) {
if (visited[start] == true) return;
visited[start] = true;
cout << start << " ";
// 정점이 여러 개인 경우에는 정점 번호가 작은 것을 먼저 방문
sort(graph[start].begin(), graph[start].end());
for (int i = 0; i < graph[start].size(); i++) {
int next = graph[start][i];
DFS(next);
}
}
void BFS(int start) {
queue<int> q;
q.push(start);
visited[start] = true;
while (!q.empty()) {
int cur = q.front();
q.pop();
cout << cur << " ";
for (int i = 0; i<graph[cur].size(); i++) {
int next = graph[cur][i];
if (!visited[next]) {
q.push(next);
visited[next] = true;
}
}
}
}
'CS > Algorithm' 카테고리의 다른 글
| 문자열 매칭 알고리즘 (0) | 2020.02.25 |
|---|---|
| Greedy Algorithm (0) | 2020.02.25 |
| Tree, Traversal, Binary Search Tree (0) | 2020.02.25 |
| 탐색2 : Hashing (0) | 2020.02.25 |
| 탐색1 : 선형탐색, 이진탐색 (0) | 2020.02.25 |