* 함수
- 명명 규칙 : 소문자로만 구성, 스네이크케이스
* 클래스
- 명명규칙 : 대문자로 시작, 카멜케이스
* 사용자 입력 받기
- input() : 문자열 입력받음
- eval() : 인자를 분석하여 evalute하는 함수, 문자열->숫자 변환가능, 수식계산가능, 함수호출가능...
- num = int(str) // 문자열 -> 정수로 변환하는 함수
* for문
for i in range(a) => i : 0~(a-1)
for i in range(a,b) => i : a~(b-1)
산술연산
+
-
*
** : 제곱연산
/ : 실수 나눗셈
// : 정수 나눗셈
% : 나머지연산
type(parameter) : parameter의 타입반환
print( a, end = ' ') // 줄바꿈대신 ' '출력
print(1,2,3, sep=',' , end = '_') // 원소사이에 , 를 삽입하고 마지막에 _ 출력 => 1,2,3_
리스트형 자료형의 연산
1. 덧셈연산 : [1,2] + [1,2,3] = [1,2,1,2,3,]
2. 곱셈연산 : [1,2,3] * 2 = [1,2,3,1,2,3]
3. 인덱싱 연산 : list = [1,2,3] print(list[0], list[-1]) // 1 3
4. 슬라이싱 연산 : list[1:3] = [0,0,0,0,0] list[:3] = [0,0,0,0,0] list[2:] = [0,0,0,0] even = list[0:10:2]
리스트자료형 함수
len(list) : list의 길이 반환
min(list) : list의 값들 중 가장 작은 값 반환
max(list) : list의 값들 중 가장 큰 값 반환
list.remove(a): list에서 첫번째 a값을 찾아서 삭제
list.append(a) : list 끝에 a 추가
list.extend(list2) : list끝에 list2 추가
list.clear() : list 내용 전부 삭제
list.insert(i, a) : list[i] 에 a 삽입
list.pop(i) : list[i] 반환및 삭제
list.count(a) : list에 속한 a 갯수 반환
list.index(a) : list의 첫번째 a의 인덱스 반환
문자열 자료형
- 작은따옴표 또는 큰따옴표로 묶을 수 있다
- 리스트 자료형과 비슷 : 덧셈연산, 곱셈연산, 인덱싱연산, 슬라이싱연산 (단! 문자열은 인덱싱연산으로 내용 바꿀 수 없다!)
문자열 함수
str.count(sub) : str에 sub이 등장하는 횟수 반환
str.lower() : str내용 전부 소문자로 바꾼 문자열 반환
str.upper()
str.lstrip() : str의 왼쪽 공백 모두 제거한 문자열 반환
str.rstrip() : str의 오른쪽 공백 모두 제거한 문자열 반환
str.strip() : 왼쪽 오른쪽 공배 모두 제거한 문자열 반환
str.replace(old,new) : str의 모든 old를 new로 교체한 문자열 반환
str.replace(old,new,2) : str의 두번째 old까지 new로 교체한 문자열 반환
str.split(' ') : str을 ' ' 기준으로 나눠서 리스트에 담아서 반환
str.isdigit() : str이 숫자로만 이루어져 있으면 True, 아니면 False
str.isalpha() : str이 알파벳만으로 이루어져 있으면 True, 아니면 False
str.startswith(prefix) : str이 prefix로 시작하면 True, 아니면 False
str.endswith(suffix) : str이 suffix로 끝나면 True, 아니면 False
문자열 탐색함수
str.find(sub) : str의 앞에서부터 sub을 찾아서 sub가 있으면 해당 인덱스값 반환, 없으면 -1 반환
str.rfind(sub) : str의 뒤에서부터 sub를 찾아서 sub가 있으면 해당 인덱스값 반환, 없으면 -1 반환
in 연산자
if 'sub' in str // str에 sub 있으면 True, 아니면 False
if a in list // list에 a 있으면 True, 아니면 False
not in 연산자
if 'sub' not in str // str에 sub 없으면 True, 있으면 False
if a not in list // list에 a 없으면 True, 있으면 False
함수 종류
- 객체 안에 있는 함수 : 해당 객체에 특화된 형태
- 객체 밖에 있는 함수 : 둘이상의 다양한 종류의 값을 대상으로 동작하는 함수
bool 자료형
True
False
다른 자료형과 bool 자료형
0 = False
0이 아닌 수 = True
빈리스트 = False
비어있지 않은 리스트 = True
빈 문자열 = False
비어있지 않은 문자열 = True
조건문
if ~ elif ~ elif ~ else
반복문1
while 조건 :
조건이 True인 동안 반복실행될 문장
반복문2
for 변수 in 반복범위 :
범위동안 반복실행될 문장들
튜플
- 리스트와 비슷하지만 ( a,b,c... )로 표현
- 튜플은 값을 추가하거나 수정할 수 없다
튜플 관련 함수
len()
max()
min()
tuple.count(a)
tuple.index(a)
덧셈연산
곱셈연산
인덱싱연산
슬라이싱연산
레인지
- 레인지 객체는 '값의 범위'를 나타낸다
- range(1,10) = range(1,10,1)
- range(1,10,2) : 1부터 2씩 증가하여 9까지
- 거꾸로 범위 지정 : range(10,1,-1) -> 10부터 2까지 -1씩 감소하는 정수
형변환
list(str)
list(range)
list(tuple)
tuple(str)
tuple(range)
tuple(list)
str(list)
str(tuple)
함수
- 디폴트값 : 디폴트 값을 가지는 매개변수는 뒤에 위치해야한다
- 매개변수 "참조" 관계 : 파이썬에서는 매겨변수를 위해 별도의 메모리 공간을 할당하지 않는다. 따라서 매개변수는 참조 형식으로 함수내부에서 접근된다
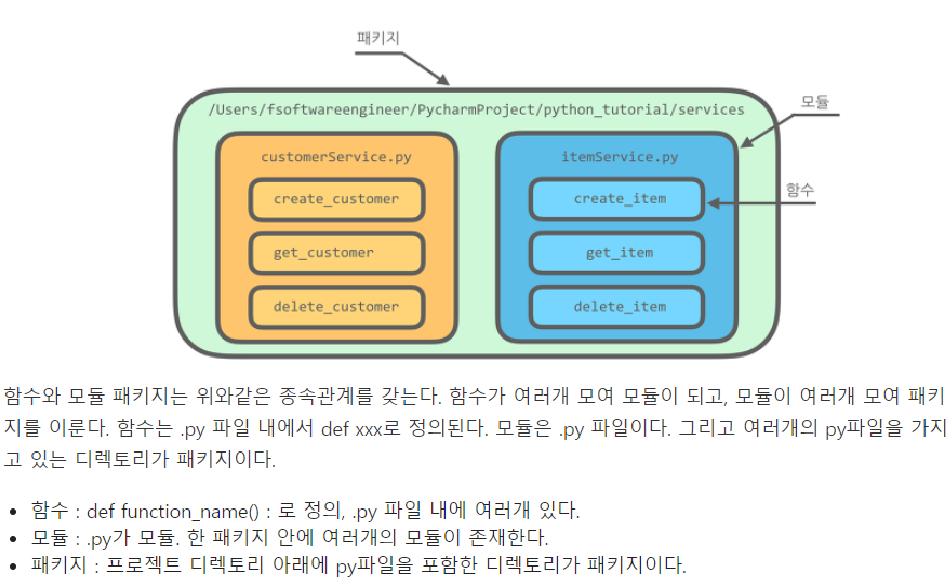
모듈
- 정의 : 모듈이란 함수나 변수 또는 클래스를 모아 놓은 '파일'
- import 모듈이름
- import 모듈 as 새로운모듈이름
- from 파일이름 import 함수1 (as 새로운함수이름)
- from 파일이름 import 함수1, 함수2
- from mod1 import *
math 모듈
- math.pi
- math.e
- math.log(x) = lnx
- math.sqrt(x) = x^1/2
- math.fabs(x) = |x|
etc
패키지
- 패키지(Packages)는 도트(.)를 사용하여 파이썬 모듈을 계층적(디렉터리 구조)으로 관리할 수 있게 해준다.
- 파이썬 패키지는 디렉터리와 파이썬 모듈로 이루어진다
딕셔너리 자료형
- 딕셔너리는 Key와 Value를 한 쌍으로 갖는 자료형
- value는 중복되어도 되지만 key는 중복되어서는 안된다
- 딕셔너리의 데이터는 저장 순서 중요하지 않다
- 딕셔노리를 대상으로 for문 구성이 가능 -> 딕셔너리의 'key'를 가지고 for문 동작
- dic = { 'key1' : value1, 'key2' : value2 }
- 참조 : dic[key1]
- 수정 : dic[key1] += 10
- 추가 : dic[newKey] = newValue
- 삭제 : del dic[key1]
- value1 in dic // True
set 자료형
- 집합 자료형은 set 키워드를 사용, set()의 괄호 안에 리스트를 입력하거나 문자열을 입력
s1 = set([1,2,3]) >>> s1 = {1, 2, 3}
s2 = set("Hello") >>> s2 = {'e', 'H', 'l', 'o'}
- 중복을 허용하지 않는다
- 순서가 없다(Unordered). => set 자료형은 순서가 없기(unordered) 때문에 인덱싱으로 값을 얻을 수 없다.
- set 자료형에 저장된 값을 인덱싱으로 접근하려면 다음과 같이 리스트나 튜플로 변환한후 해야 한다.
- 교집합 : s1 & s2 || s1.intersection(s2)
- 합집합 : s1 + s2 || s1.union(s2)
- 차집합 : s1 - s2 || s1.difference(s2)
- 값 1개 추가 : s1.add(4)
- 값 여러개 추가 : s1.update([4, 5, 6])
- 특정 값 제가 : s1.remove(2)
지역변수
- 함수 안에서 선언되는 변수
- 함수내에서 만들어 졌다가 함수를 벗어나면 사라진다
- 함수 밖에서 지역변수 접근 불가능
전역변수
- 함수 밖에서 선언되는 변수
- 함수 내에서 전역변수 접근하려면 global 키워드 사용
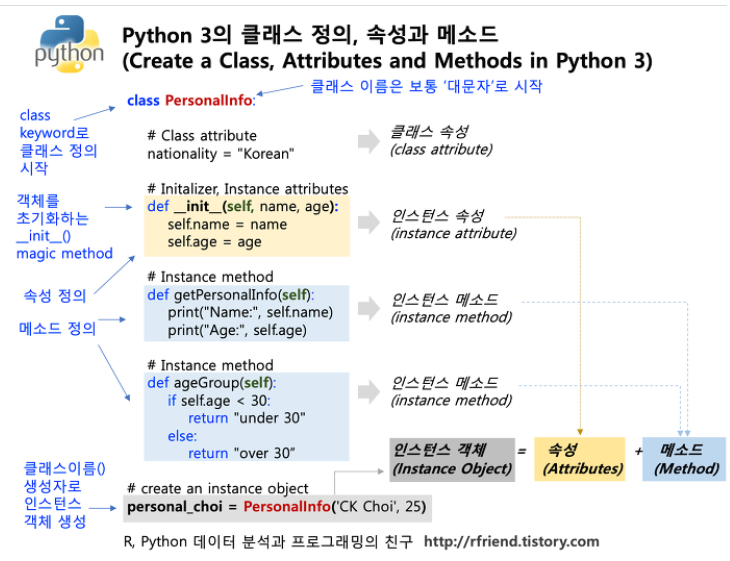
클래스와 객체
- 클래스 : 특정 객체를 생성하기 위해 변수와 메소드를 정의하는 템플릿
- 객체 : 속성(변수)과 행동(메소드)을 가지는 표현하려는 대상
- 인스턴스 : 클래스를 통해 실제 생성된 객체
- 인스턴스 변수(속성) : 인스턴스 안에 존재하는 변수
- 인스턴스 메소드 : 인스턴스 안에 존재하는 함수
- 일반 함수와는 달리 파이썬에서 객체의 메서드의 첫 번째 매개변수 self는 객체 자기자신이다.
- 생성자 : 인스턴스 생성시 변수의 초기화를 동시에 진핼하는 함수 => def __init__( )
- 파이썬의 모든 데이터는 객체! => 문자열, 정수, 실수 모든 값들은 객체이다
특정 예외 여러개 처리
try :
실행문장
except 예외1 (as 변수1) : // 변수1에 오류메세지 저장된다
예외1 발생시 실행문장
except 예외2 (as 변수2) : // 변수2에 오류메세지 저장된다
예외2 발생시 실행문징
finally :
try영역에 진입하면 예외 발생 유무 상관없이 무조건 실행해야 하는 내용
모든 예외처리
try :
실행문장
except :
어떤 예외가 발생하던 실행되는 문장
'Python > python' 카테고리의 다른 글
| 파이썬 기본 문법 4 : 예외처리 (0) | 2020.03.16 |
|---|---|
| 파이썬 기본 문법 3 : 클래스, 모듈, 패키지 (0) | 2020.03.16 |
| 파이썬 기본 문법 2 : 제어문, 함수, 입출력 (0) | 2020.03.16 |
| 파이썬 기본 문법 1 : 자료형 (0) | 2020.03.16 |