1. 문제해결과 알고리즘
- 문제해결과정
- 알고리즘 분석
2. 데이터 추상화와 자료구조
- 데이터 추상화
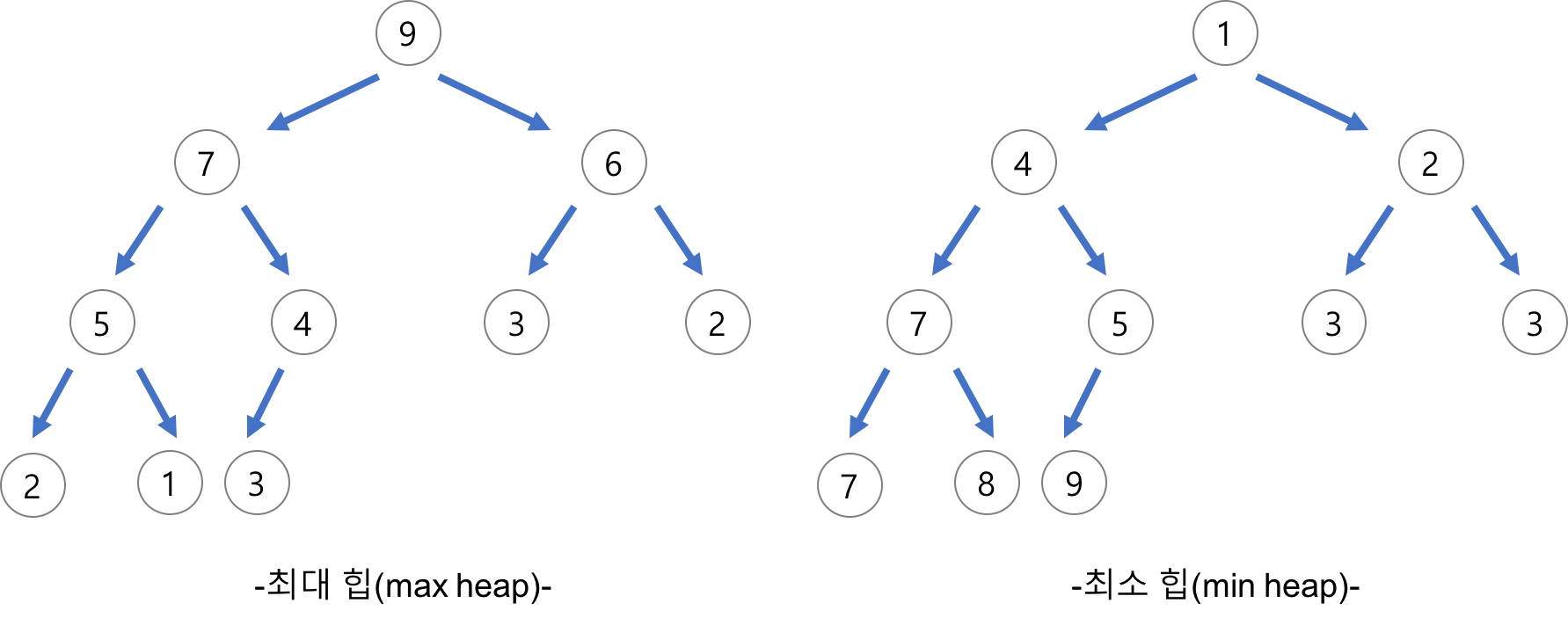
- 자료구조 : tree, binary tree, stack, queue, heap, union-find, dictionary, ...
4. Sorting
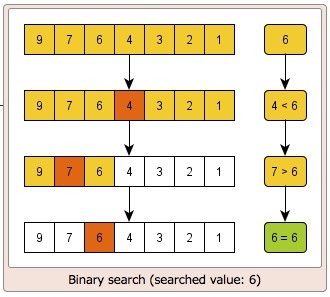
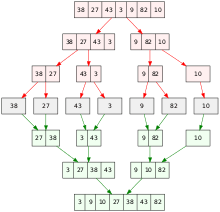
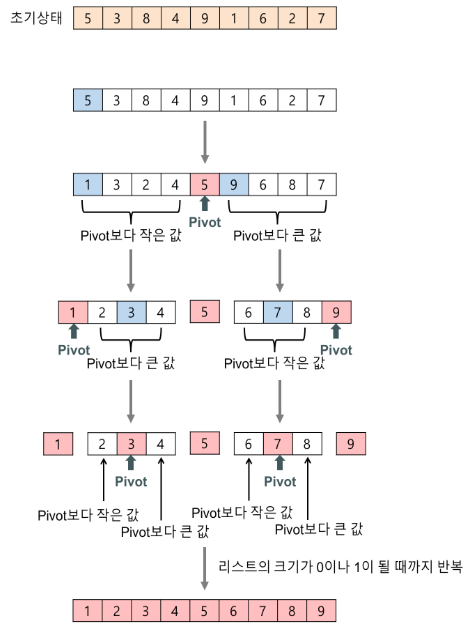
- 정렬 : insertion sort, quick sort, merge sort, heap sort, radix sort
6. Dynamic sets & Searching
- array doubling & amortized analysis
- BST
- Red-Black tree
7. Graph and Graph Search
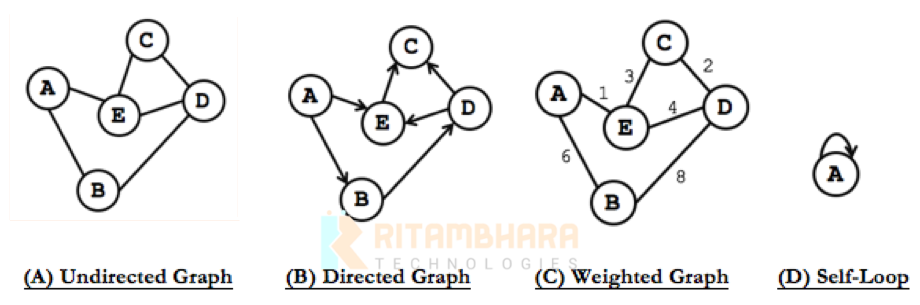
- Graph
- Graph traversal : pre-order, in-order, post-order
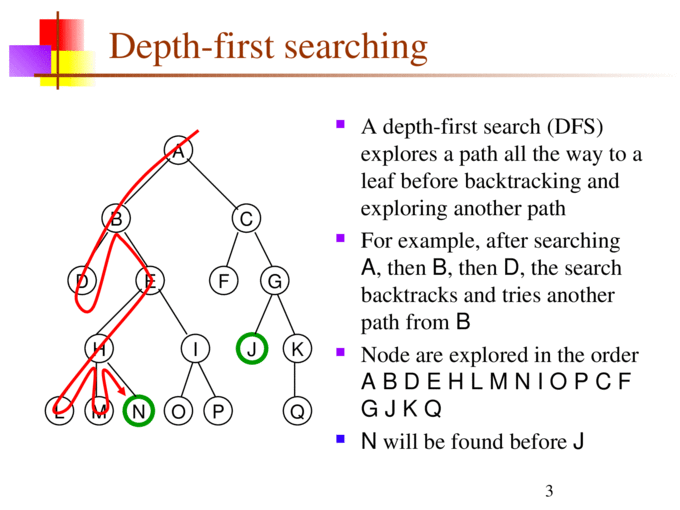
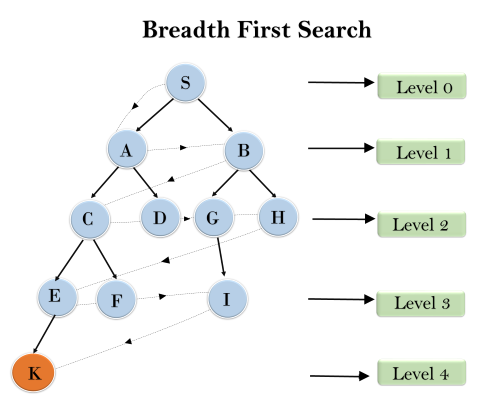
- Graph search : DFS, BFS
- Strongly Connected Components
8. Graph optimization problem & greedy algorithm
- optimization problem
- graph optimization problem : MST, shortest path
- MST -> Prim algorithm, Kruskal algorithm
- shortest path -> dijkstra algorithm
9. Transitive Closure & All-pairs shortest paths
- transitive closure, Floyd-Warshall algorithm
- All-pairs shortest paths
10. Dynamic Programming
- dynamic programming & recursive algorithm
- Matrix-chain Multiplication
11. String Match
- string match
- Brute-Force
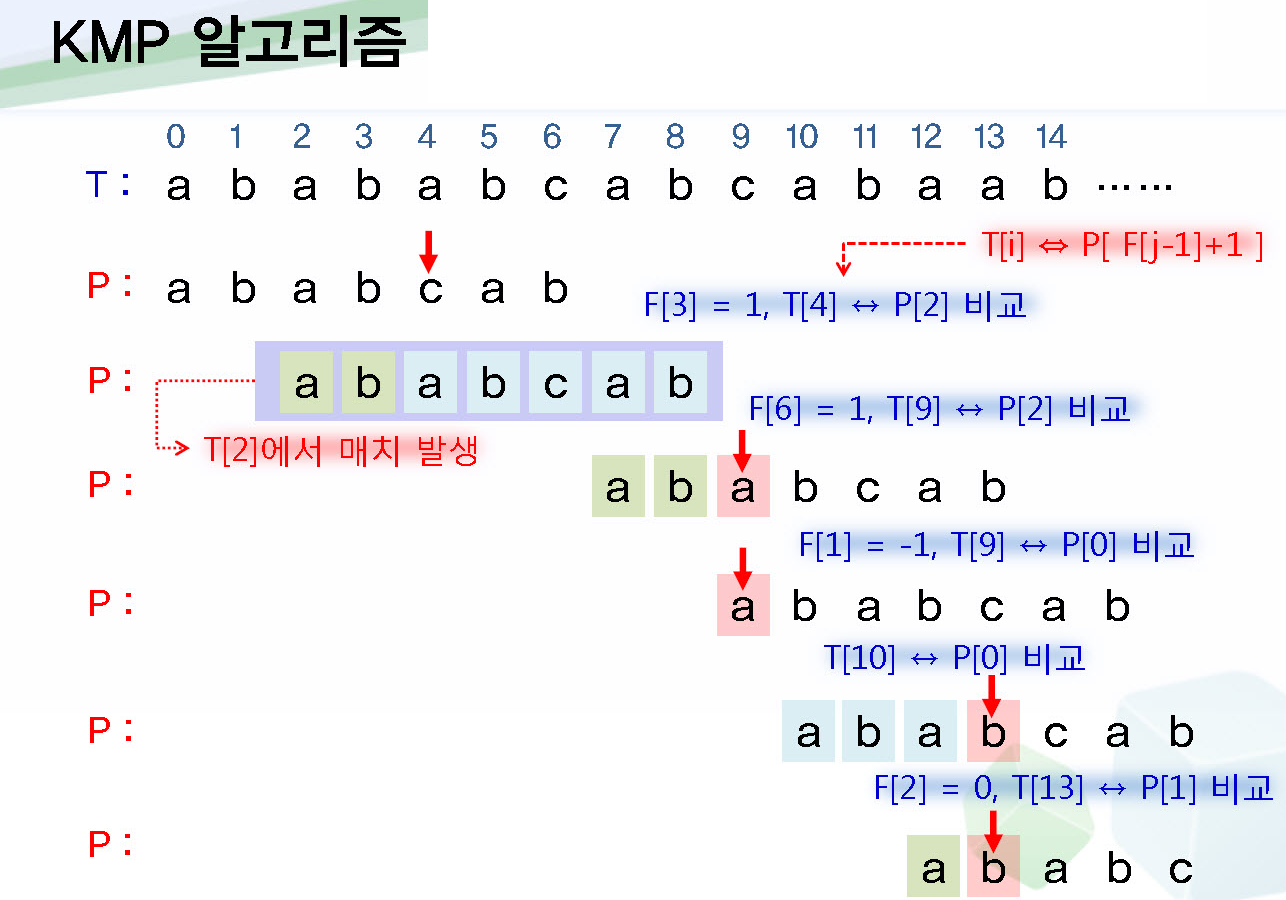
- KMP
- Boyer-Moore
13. NP-Complete Problem
- Optimization problem vs Decision problem
- Class P, Class NP, Class NP-hard problem
- Class NP-Complete problem
'CS > Algorithm' 카테고리의 다른 글
| 문자열 매칭 알고리즘 (0) | 2020.02.25 |
|---|---|
| Greedy Algorithm (0) | 2020.02.25 |
| Graph, DFS, BFS, Dijkstra (0) | 2020.02.25 |
| Tree, Traversal, Binary Search Tree (0) | 2020.02.25 |
| 탐색2 : Hashing (0) | 2020.02.25 |