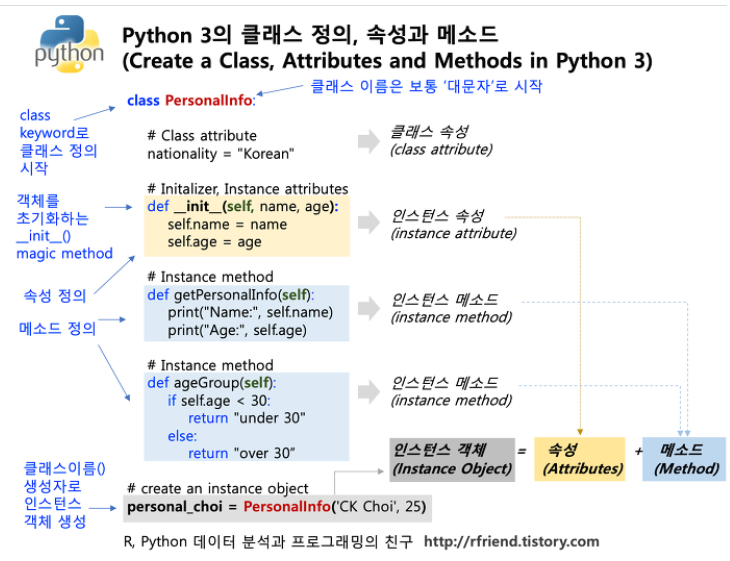
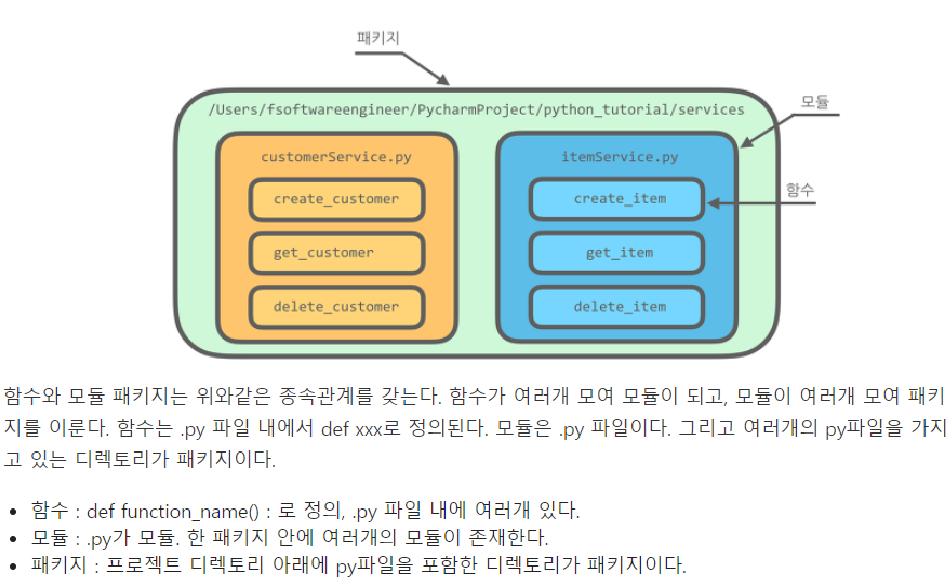
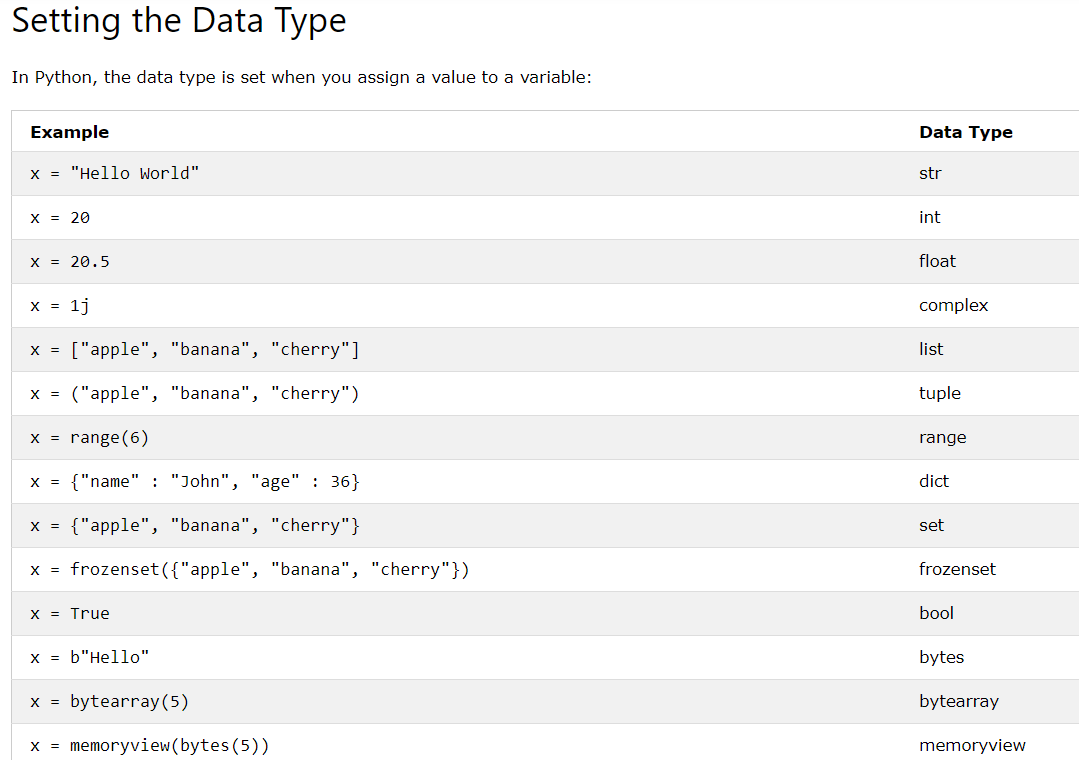
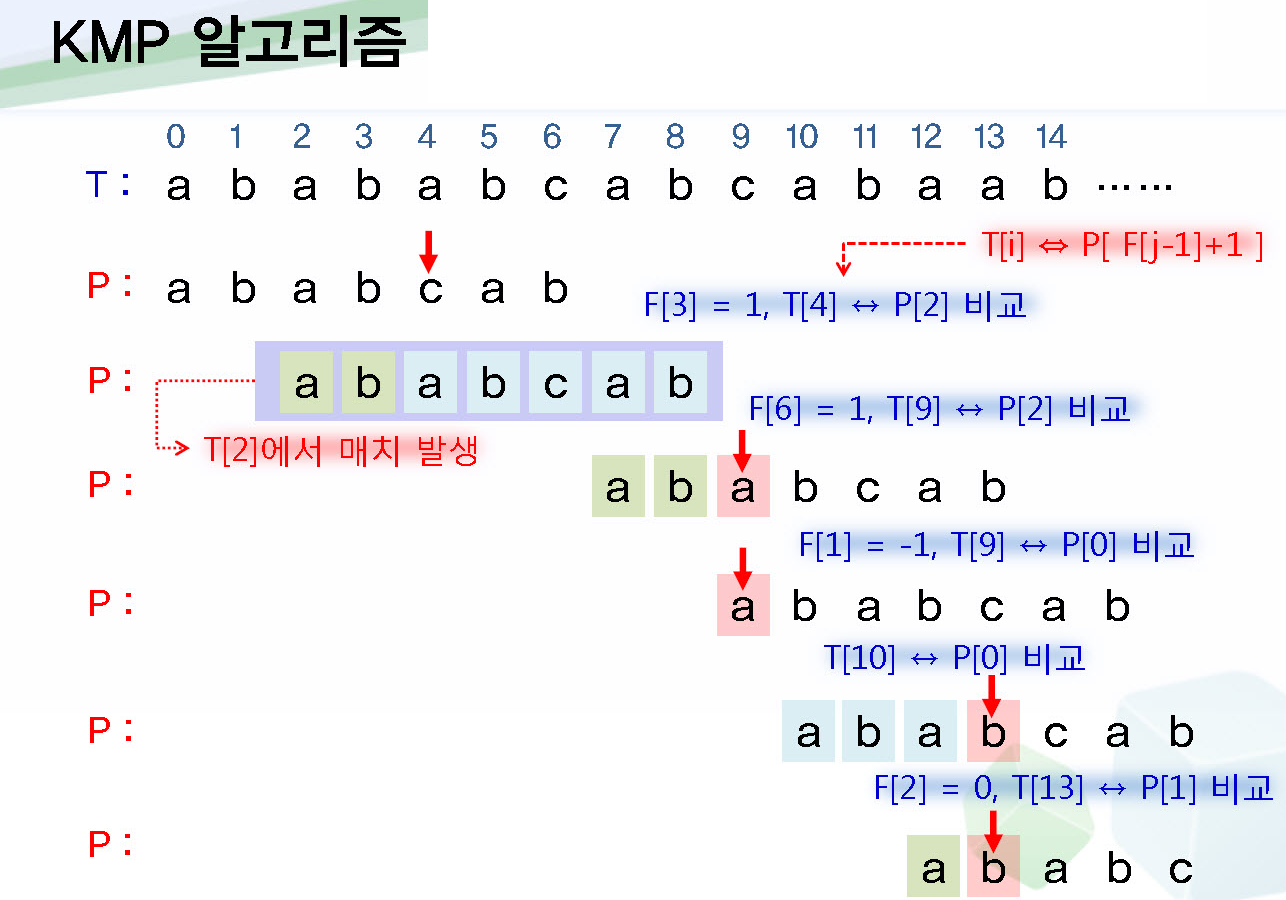
분류 : 데이터들을 특정 기준으로 나눌 수 있는 ‘선형구분자’를 설정하여 분류. 오차를 이용하여 구분자의 기울기를 조정하는 것을 ‘학습’이라고 한다.
- Error = target – actual
Learning rate(L) : 학습률은 업데이트의 정도를 저장
update parameter : new A = A + dA = A + L(E/x).
예측 : 새로운 data가 들어오면 구분자에 의해 어떤 output으로 분류될지 판단 => 예측과 분류는 다른 것이 아님
XOR 문제의 경우 선형분류자는 하나가 아니다 -> 여러개의 선형 분류자를 이용 -> 인공신경망은 여러개의 분류자가 함께 동작
인공신경망
인공뉴런은 X1부터 Xn까지 입력 값에 각각 W1부터 Wn까지의 가중치를 곱하고 그 모든 합이 임계치(threshold)가 초과되면 출력값이 발생
activation functoin(활성화 함수) : 여러 입력신호를 받아 특정 threshold를 넘어서는 경우에 출력 신호를 생성하는 함수 -> sigomoid 함수(=logistic 함수)가 대표적이다. => y = 1 / (1+ e^-x)
인공신경망 : 상호연결된 생물학적 뉴런을 인공적으로 모델화 한 것으로, 다수의 인공뉴런을 가지고 있는 layer를 여러 층으로 쌓은 후 이전 layer와 이후 layer의 모든 인공뉴런들이 연결되어 있다. 이때 각각의 연결에 weight(가중치)가 존재하는데 학습과정을 통해 weigjt값들을 조정함으로써 input에 대해 올바른 output이 나올 수 있도록 한다.
- 인공 뉴런이 계산한 출력 값과 사용자가 기대하는 출력 값을 비교. => Error = target – actual
back propagation : error 정보가 뒤쪽으로 계속 전파
중간 계층에 존재하는 노드들의 오차는 출력계층 노드들의 오차를 가중치에 크기에 비례해 나눠서 back propagation
back propagation은 행렬곱으로 표현 : Error(hidden) = W.T(hidden-output) * Error(output)
가중치 업데이트 : 함수의 최저점을 구하는 Gradient Descent 기법을 학습 목표 값과 실제 값 간의 차이를 구하는 Error function에 적용 -> error function = (target-actual)^2인 이차함수 이므로 error function의 최저점은 error function의 기울기(dE/dw)가 가장 작은 지점 -> dE/dw = -> new W = old W – (LearningRate * (dE/dw))
if __name__ == "__main__"을 사용하면C:\>python mod1.py처럼 직접 이 파일을 실행했을 때는__name__ == "__main__"이 참이 되어 if문 다음 문장이 수행된다. 반대로 대화형 인터프리터나 다른 파일에서 이 모듈을 불러서 사용할 때는__name__ == "__main__"이 거짓이 되어 if문 다음 문장이 수행되지 않는다.
모듈에 있는 변수 클래스 사용
#mod2.py 작성
PI = 3.141592
class Math:
def solv(self, r):
return PI * (r ** 2)
def add(a, b):
return a+b
모듈 안에 있는 변수 및 클래스를 사용하려면 "."(도트 연산자)로 클래스 이름 앞에 모듈 이름을 먼저 입력해야 한다.
5. game 패키지를 참조할 수 있도록 명령 프롬프트 창에서 set 명령어로PYTHONPATH환경 변수에C:/ 디렉터리를 추가
C:\> set PYTHONPATH=C:/
C:\> python
Type "help", "copyright", "credits" or "license" for more information.
>>>
패키지 안의 함수 실행
1. echo_test 함수를 실행
# echo 모듈을 import하여 실행
>>> import game.sound.echo
>>> game.sound.echo.echo_test()
echo
# echo 모듈이 있는 디렉터리까지를 from ... import하여 실행
>>> from game.sound import echo
>>> echo.echo_test()
echo
# echo 모듈의 echo_test 함수를 직접 import하여 실행
>>> from game.sound.echo import echo_test
>>> echo_test()
echo
2. import game을 수행하면 game 디렉터리의 모듈 또는 game 디렉터리의__init__.py에 정의한 것만 참조
>>> import game
>>> game.sound.echo.echo_test()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'module' object has no attribute 'sound'
3. 도트 연산자(.)를 사용해서 import a.b.c처럼 import할 때 가장 마지막 항목인 c는 반드시 모듈 또는 패키지여야만 한다.
>>> import game.sound.echo.echo_test
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: No module named echo_test
__init__.py : __init__.py 파일은 해당 디렉터리가 패키지의 일부임을 알려주는 역할을 한다.
특징 : 탐욕알고리즘은 최적해를 구하는 데에 사용되는 근사적인 방법으로, 여러 경우 중 하나를 결정해야 할 때마다 그 순간에 최적이라고 생각되는 것을 선택해 나가는 방식으로 진행하여 최종적인 해답에 도달한다. 순간마다 하는 선택은 그 순간에 대해 지역적으로는 최적이지만, 그 선택들을 계속 수집하여 최종적(전역적)인 해답을 만들었다고 해서, 그것이 최적이라는 보장은 없다.
예시코드
// boj - 5585 : greedy algorithm
#include<iostream>
using namespace std;
int main() {
int monney;
cin >> monney;
monney = 1000 - monney;
int res = 0;
// 500
int p = monney / 500;
res += p;
monney -= (500 * p);
// 100
p = monney / 100;
res += p;
monney -= (100 * p);
// 50
p = monney / 50;
res += p;
monney -= (50 * p);
// 10
p = monney / 10;
res += p;
monney -= (10 * p);
// 5
p = monney / 5;
res += p;
monney -= (5 * p);
// 1
p = monney / 1;
res += p;
monney -= (1 * p);
cout << res << endl;
return 0;
}