1. 기본태그
<title> : 페이지 제목으로 <head> 내에서만 작성
<meta> : 웹 페이지의 메타데이터를 표현하기위해 사용
<h1> ~ <h6>
- 문단 제목, 블록태그
- title 속성 : tooltip(설명문) 출력 (ex. <h1 title="h1 tag"> )
<p> : 단락 나누기, 블록태그
<hr> : 수평선 긋기
<br> : 새로운 줄로 넘어가기
html entities
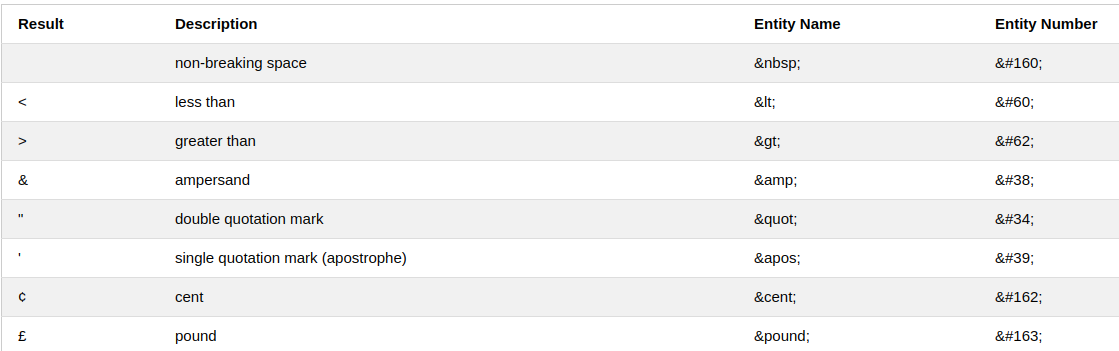
- html문서에서 예약어로 사용되고 있는 문자나 기호는 html entities를 이용하여 입력
<pre> : 개발자 포맷 그대로 출력
<strong> : 굵게 강조
<i> : 이탤릭체로 강조
<del> : 취소선
<ins> : 밑줄
<mark> : 하이라이팅
<div>
- 블록을 구성하기 위한 컨테이너로 사용되는 블록태그
- 블록태그는 항상 새 라인에서 시작하고 기본적으로 가로폭 전체 넓이를 가지는 직사각형 형태
<span>
- 텍스트 일부분에 스타일링을 하거나 JS로 제어하기 위해 사용되는 인라인 태그
- 인라인태그는 블록에 삽입되어 블록 콘텐트의 일부를 표현하는데 사용
<img>
- 이미지 삽입 태그
- src 속성 : 이미지파일의 url, 필수 속성
- alt 속성 : 이미지를 출력할 수 없는 경우 출려되는 문자열, 필수 속성
- width 속성 : 이미지 너비, 생략시 원본의 너비
- height 속성 : 이미지 높이, 생략시 원본의 높이
<ol> : 순서 있는 리스트
<ul> : 순서 없는 리스트
<li> : 리스트 아이템
<dl>
- definition list
- <dt> : 용어
- <dd> : 설명
<table>
- 표 전체를 담는 컨테이너
- <caption> : 표제목
- <thead> : 헤드
- <tbody> : 바디, 데이터 표현
- <tfoot> 바닥
- <tr> : 행, 여러개의 <td>, <th> 포함
- <th> : 제목 셀
- <td> : 데이터 셀
2. 하이퍼링크
<a>
- 하이퍼링크 태그
- href 속성 : 이동할 html 페이지의 url 또는 html 페이지 내의 앵커 ( 앵커는 id속성으로 지정)
- target 속성 : 연결된 html 페이지가 출력될 윈도우 지정
- _blank : 새창에서 열기
- _self : 현재창에서 열기
- _parent : 부모창에서 열기
- _top : 최상위 창에서 열기
- iframe_name : 해당 인라인프레임에서 열기
- download 속성 : 링크 클릭시 href에 지정된 파일 다운로드 시작
3. 인라인 프레임
<iframe>
- 현재 html 페이지 내에 내장 윈도우를 만들고 다른 html 페이지를 출력
- src 속성 : 출력할 html 페이지 url
- name 속성 : 프레임 윈도우 이름 -> 다른 웹 페이지에서 <a> 태그의 target 속성 값으로 사용됨
4. 미디어
- 미디어 표준화
: html5 이전에는 오디오나 비디오를 재생하기 위해 플러그인 소프트웨어를 설치해야 했고 브라우저마다 설치해야되는 플러그인이 달라 브라우저에 따라 미디어가 재생되지 않는 문제점이 있었다. html5에서는 플러그인 없이 오디오나 비디오를 재생할 수 있도록 미디어 태그를 이용하여 표준화 시켰다.
<video>
- src : 비디오 파일의 url
- width, height : 비디오 재생 영역의 너비와 높이
- controls : 비디오 제어 버튼
- autoplay : 비디오 로딩 즉시 재생
- loop : 비디오 반복 재생
- type : 비디오의 MIME type 설정 = video/mp4 | video/webm | video/ogg
<audio>
- src : 오디오 파일의 url
- controls : 오디오 제어 버튼
- autoplay : 오디오 로딩 즉시 재생
- loop : 반복 재생
5. 문서구조화
- 시맨틱 웹
: 웹 문서를 구조화 하여 의미 있는 내용 탐색이 용이한 웹
- 시맨틱 태그
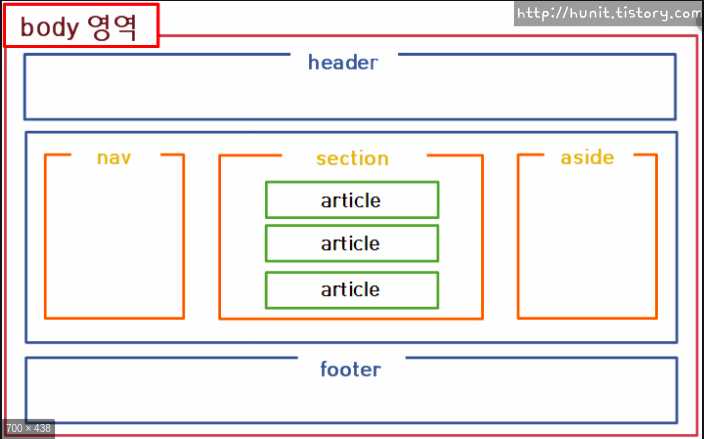
- <header> : 페이지나 <section>의 머리말을 표현하는 태그
- <nav> : 하이퍼링크들을 모아 놓은 섹션. ex) 페이지 내 목차
- <section> : 본문의 콘텐츠를 분류
- <article> : 콘텐츠의 실질적인 내용
- <aside> : 본문의 흐름에서 약간 벗어난 내용
- <footer> 페이지나 <section>의 꼬리말
<figure>
- 본문에 삽입된 그림, 이미지, 동영상등을 블록화하는 시맨틱 블록 태그
- <figcaption>으로 <figure>태그의 제목을 붙인다
<time> : 시간정보임을 표시하는 시맨틱 인라인 태그
<meter>
- 퍼센테지를 나타내는 시맨틱 인라인 태그
- value 속성 : 0~1 사이의 값으로 비율 표현
<progress>
- 작업의 진행 정도를 표시하는 시맨틱 인라인 태그
- value 속성, max 속성 : max속성값 기준 value 값의 비율 표현
6. 웹 폼
- 개념
- 웹 페이지를 통해 사용자 입력을 받는 폼을 web form 이라고 한다.
- web from을 구성하는 태그들을 form element라고 한다. ex) <input>, <select>, <button>
<form>
- 웹 폼을 구성하는 폼 태그들을 담는 컨테이너
- name 속성 : 폼이름 지정
- action 속성 : 폼 데이터를 처리할 웹 서버 응용프로그램의 url
- method 속성 : 폼 데이터를 웹 서버로 전송하는 형식 지정 = "GET|POST"
- 텍스트 입력 form element
- <input type="text"> : 한줄 텍스트를 입력받음
- <input type="password"> : 비밀번호 입력받음
- <textarea cols="20" rows="5"> : 20 x 5 크기의 여러줄의 텍스트 입력 받음
- <input type="text" list="datalistId"> : 데이터 목록을 가진 텍스트 입력
<datalost id = "datalistId">
<option value="listItem1">
<option value="listItem2">
</datalist>
- 버튼 form element
- <button type="button"> : 단순버튼, JS 코드에서 주로 이용
- <button type="submit"> : submit 버튼
- <button type="reset"> : 폼에 입력된 내용 모두 지우고 초기화하는 버튼
- <button type="button"> : 이미지버튼
<img src="imageUrl" alt="이미지버튼">
</button>
- 선택형 form element
- <input type="checkbox" value="요소 값" name="요소 이름" checked>
- 각각의 체크박스를 선택/해제 하는 폼 요소
- value 속성 : 폼 요소가 선택된 상태일 때 웹서버에 전송되는 값
- checked 속성 : 이 속성이 설정되어 있으면 초기에 선택 상태로 출력
- <input type="radio" value="요소 값" name="요소 이름 checked>
- 가은 name 값을 가진 radio 버튼들이 하나의 그룹을 형성하고 그 중 하나만 선택되는 폼 요소
- <select name="요소이름" size="5">
<option value="1">option1</option>
<option value="2">option2</option>
</select>- 드롭다운 목록을 보여주고 그 중 하나를 선택하는 폼 요소
- size 속성 : 드롭다운 목록에 보여지는 항목 갯수
<input type="color" value="초기값">
- color 입력 form element
<input type="month | week | date | time | datetime-local">
- 시간정보 입력 form element
- 특정형식 입력 form element
- <input type="email"> : email 주소 형식으로 입력하지 않고 submit 하는 경우 오류메세지를 출력
- <input type="url"> : url 형식으로 입력하지 않고 submit 하는 경우 오류메세지 출력
- placeholder 속성
- 입력할 정보의 예시를 보여주는 속성
- <input type="tel" placeholder="010-0000-0000">
- form element caption 설정 : 라벨링
- caption : 폼 요소 앞에 붙는 간단한 설명이나 이름
- 라벨링1
<label>
캡션 : <input type="text">
</label> - 라벨링2
<label for="formId">
캡션 :
</label>
<input type="text" id="formId">
- 다수의 form element를 grouping
- <fieldset> : 폼 요소들을 감싸서 그룹핑. 브라우저는 그룹을 둘러싸는 외곽선 출력
- <legend> : 그룹핑된 그룹의 제목
- <form>
<fieldset>
<legend>회원정보</legend>
이름 : <input type="text"><br>
메일 : <input type="email">
</fieldset>
</form>
'CS > Web Programming' 카테고리의 다른 글
| #4 Responsive Web (0) | 2020.02.04 |
|---|---|
| #3 Basic Javascript (0) | 2020.02.04 |
| #2 CSS3 (0) | 2020.02.04 |
| #0 Web introduction (0) | 2020.02.03 |